iOS 11에서 CoreML과 TensorFlow로 스마트 제스처 인식하기
2017.09.18
#CoreML • #TensorFlow
by Adam King, translated by pilgwon
1부에서, 저는 딥러닝을 사용해 하트 모양이나 체크 모양 또는 웃는 얼굴과 같은 복잡한 제스쳐를 모바일 기기에서 인식하는 방법을 보여드렸었습니다. 또한 이런 제스쳐를 사용하는 앱이 어떤 이익을 얻을 것인지에 대해 설명했고, 그것에 대한 UX 측면에서 살펴보았습니다.
이번 시간에는 저는 그런 아이디어를 우리의 앱에서 구현하는 방법의 기술적인 측면을 살펴볼 것입니다. 그리고 또한 애플의 (iOS 11에서 새로 나온) Core ML 프레임워크를 설명하고 사용해 볼 것입니다.
 매 스트로크가 끝날 때 마다 복잡한 제스쳐를 실시간 인식합니다
매 스트로크가 끝날 때 마다 복잡한 제스쳐를 실시간 인식합니다
이 기술은 머신 러닝을 이용해서 제스쳐를 1차적으로 인식합니다. 최대한 많은 개발자들에게 닿기 위해, 저는 이 분야에 대한 아무 이해도 없다 가정할 것입니다. 이 게시글의 몇몇 부분은 iOS 특화되어있지만, 안드로이드 개발자들도 얻을 것이 있습니다.
완성된 프로젝트의 소스 코드는 여기서 확인 가능합니다. 만약 당신이 따라가기 힘든 부분이 있다면, 저에게 연락하는 것을 편하게 생각해주세요.
우리는 무엇을 만드나요?
튜토리얼의 마지막에서는, 우리는 커스텀 제스쳐를 선택할 수 있고 iOS 앱에서 높은 정확도로 인식할 수 있는 설정을 가지게 될 것입니다. 구성 요소는 다음과 같습니다:
- 각 제스쳐에 대한 몇가지 예제를 수집할 앱 (체크 표시를 그리고, 하트를 그리고, 등등)
- 제스쳐를 인식 시키기 위해 머신 러닝 알고리즘을 훈련시킬 파이썬 스크립트. 우리는 텐서플로우를 사용할 것이지만 나중에 알아보겠습니다.
- 커스텀 제스쳐를 사용할 앱. 유저가 화면에 그리는 스트로크를 기록하고 머신 러닝 알고리즘을 사용하여 그 제스쳐가 어떤 제스쳐인지 알아냅니다.
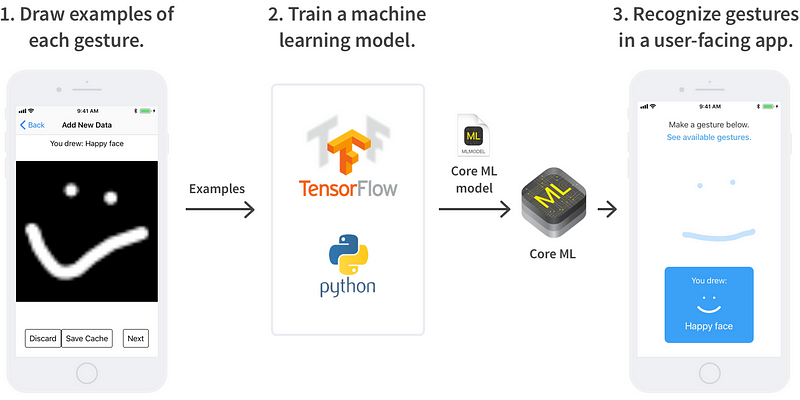 우리가 그린 제스쳐들은 Core ML을 인앱에서 평가할 머신 러닝 알고리즘을 훈련시키는 데에 사용됩니다.
우리가 그린 제스쳐들은 Core ML을 인앱에서 평가할 머신 러닝 알고리즘을 훈련시키는 데에 사용됩니다.
1부에서 저는 머신 러닝 알고리즘을 사용하는것이 왜 필수인지 거듭 살펴보았었습니다. 짧게 말해서 예를 들어보면, 유저가 만든 하트 모양을 명확하게 인식하는 코드를 작성하는 것보다 더 어렵습니다.
머신 러닝 알고리즘이 무엇인가요?
머신 러닝 알고리즘은 다른 데이터에 대한 불와전한 정보가 주어진 추론을 하기 위해 일련의 데이터로부터 학습합니다.
우리의 경우엔, 데이터는 유저가 화면에 그린 스트로크와, 그것들과 관련있는 제스쳐 클래스(“하트”, “체크 표시” 등)입니다. 우리가 추론하고자 하는 것은 제스쳐 클래스를 모르는 사용자가 만든 새로운 스트로크입니다 (불완전한 정보).
알고리즘이 데이터로 학습하게 하는 것을 “훈련”이라고 부릅니다. 데이터를 만드는 결과 추론 기계를 보통 “모델”이라고 부릅니다.
Core ML은 무엇인가요?
머신 러닝 모델은 복잡할 수 있고 (특히 모바일 기기에서) 계산하는데 느릴 수 있습니다. iOS 11에서, 애플은 앞의 행동들을 빠르고 쉽게 구현할 수 있는 Core ML 프레임워크를 발표했습니다. Core ML을 사용하면, 모델을 구현하는 것이 Core ML 모델 포맷(.mlmodel)으로 주로 저장이 됩니다. Xcode 9은 나머지를 쉽게 만들어줍니다.
공식적인 파이썬 패키지인 coremltools는 현재 사용 가능하고, mlmodel 파일들을 쉽게 저장할 수 있게 해주는 패키지입니다. 그것은 Caffe, Keras, LIBSVM, scikit-learn 그리고 XCBoost 모델로 변경할 수 있게 해주는 컨버터를 가지고 있고 게다가 앞의 것들이 충분하지 않을 경우 저수준 언어 API도 제공합니다 (예를 들어, 텐서플로우를 사용할 경우). 불행하게도 coremltools는 현재 파이썬 2.7을 필요로 합니다.
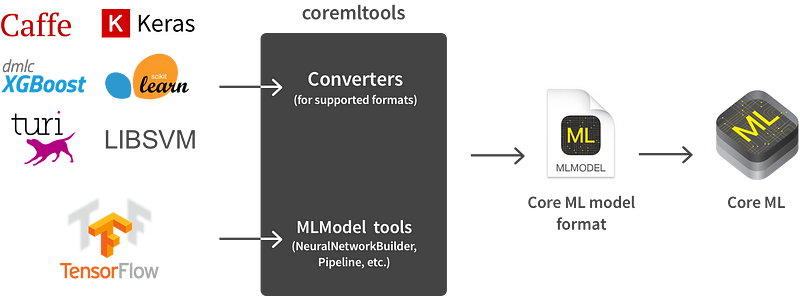 지원되는 포맷은 coremltools을 사용해 Core ML 모델로 자동으로 변환할 수 있습니다. 텐서플로우와 같이 지원하지 않는 포맷은 몇 가지 해주어야 하는 일이 있습니다.
지원되는 포맷은 coremltools을 사용해 Core ML 모델로 자동으로 변환할 수 있습니다. 텐서플로우와 같이 지원하지 않는 포맷은 몇 가지 해주어야 하는 일이 있습니다.
메모: Core ML은 모델을 계산하는 데에만 사용할 수 있고, 훈련 할 수 는 없습니다.
1. 데이터 셋 만들기
먼저 우리가 머신 러닝 알고리즘이 학습할 데이터 (제스쳐)가 있는 것을 확인해 봅시다. 사실적인 데이터 셋을 만들기 위해, 저는 기기에서 제스쳐를 입력할 수 있는 GestureInput 이라는 iOS 앱을 작성하였습니다.
만약 저와 같이 하셨다면, 당신도 GestureInput을 사용할 수 있을 것입니다. 이 앱은 여러 개의 스트로크를 입력하고, 결과 이미지를 미리 보여주며, 그 이미지를 데이터 셋에 추가하는 작업을 합니다. 당신은 또한 관련된 클래스(레이블이라고 부릅니다)를 수정할 수 있고 예제를 삭제할수도 있습니다.
GestureInput은 무작위로 제스쳐 클래스를 골라서 당신에게 예제를 그리게 할 것이고, 당신은 각각에 대해 거의 비슷한 양의 예제를 그리게 될 것입니다. 그들이 보여지는 빈도를 변경하고 싶었을 때(예. 기존의 데이터 셋에 새로운 클래스를 추가할 때), 저는 하드코딩된 값을 변경했고 컴파일을 다시 했습니다. 이쁘진 않지만, 작동은 합니다.
 머신 러닝 알고리즘의 훈련을 위한 데이터 만들기
머신 러닝 알고리즘의 훈련을 위한 데이터 만들기
이 프로젝트의 리드미는 제스쳐 클래스 셋을 어떻게 수정하는지 설명합니다. 이 제스쳐 클래스에는 체크 모양, x 모양, 오른쪽 위 대각선, 스크리블(빠르게 왼쪽 오른쪽을 왔다갔다 하면서 위나 아래로 움직이는 모양), 원, U 모양, 하트, 플러스 기호, 물음표, 대문자 A, 대문자 B, 웃는 얼굴 그리고 슬픈 얼굴이 포함되어 있습니다. 또한 당신의 기기에 옮기기만 하면 사용할 수 있는 샘플 데이터 셋이 포함되어 있습니다.
당신은 제스쳐를 얼마나 그릴 것입니까? 1부에서 말씀드렸듯이, 저는 각 제스쳐에 대해 60개의 예제를 입력하여 정확도 99.4%를 얻을 수 있었습니다. 하지만, 저는 당신에게 100개 정도 그리는 것을 추천합니다. 제스쳐를 아주 다양한 방법으로 그리면 그릴수록, 알고리즘이 그 모든것들을 배울 수 있습니다.
훈련을 위해 내보내기
GestureInput의 “래스터화” 버튼은 유저의 스트로크를 이미지로 변경하고 data.trainingset이라는 파일에 저장합니다. 이 이미지들은 알고리즘에 입력으로 사용할 것들입니다.
1부에서 다루었듯이, 저는 유저의 제스쳐(“드로잉”)를 그레이 스케일 이미지로 바꾸기 전에 사이즈 조정 후 이동하여 고정된 사이즈의 박스에 맞도록 만들었습니다. 이것은 우리의 제스쳐 인식을 유저가 어디에 그리든 얼마나 크게 그리든 상관없이 독립적으로 작동하게 만들어줍니다. 그것은 또한 빈 공간의 픽셀의 수를 최소화합니다.
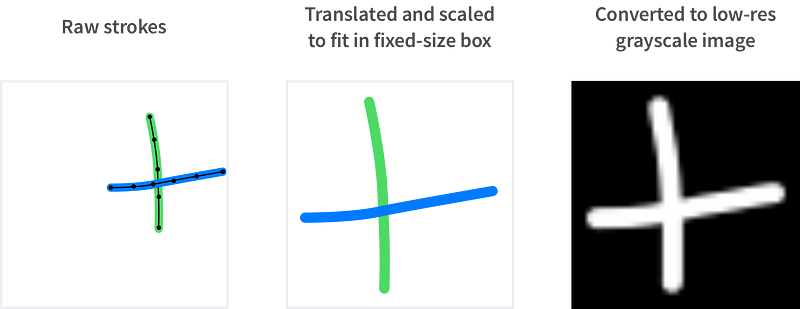 유저의 스트로크를 우리의 머신 러닝 알고리즘의 입력으로 사용하기 위해 그레이스케일 이미지로 변경하는 작업입니다
유저의 스트로크를 우리의 머신 러닝 알고리즘의 입력으로 사용하기 위해 그레이스케일 이미지로 변경하는 작업입니다
제가 여전히 터치 위치의 시간적 순서를 서로 다른 파일에 있는 각각의 스트로크를 위해 여전히 저장하고 있다는 사실을 기억하세요. 이 방법을 통해 저는 미래에 제스쳐를 이미지로 변경하는 방법을 바꿀수도 있고 또는 모든 제스쳐를 다시 그릴 필요가 없는 비 이미지 기반 접근을 인식하는데에 사용할 수도 있습니다.
GestureInput은 데이터 셋을 그것의 컨테이너의 도큐먼트 폴더안에 저장합니다. 기기에서 데이터를 가져오는 가장 쉬운 방법은 Xcode를 통해 컨테이너를 다운받는 것입니다.
2. 신경 네트워크(신경망) 훈련시키기
1단계에서 우리는 우리의 데이터셋을 이미지들의 모음(클래스 레이블과 함께)으로 변환했습니다. 이것은 우리의 제스쳐 분류 문제를 이미지 분류 문제로 변환합니다. 단지 하나의 (간단한) 제스쳐를 인식하기 위한 접근입니다. 다른 접근 방법은 속도와 가속 데이터를 사용할 것입니다.
저는 우리가 머신 러닝 알고리즘을 사용할 것이라고 말씀드렸었습니다. 현재 이미지 분류를 위한 머신 러닝 알고리즘의 최신 클래스는 CNN(나선형 신경 네트워크, Convolutional Neural Network)입니다. 이 초심자를 위한 훌륭한 CNN 설명서를 보세요. 우리는 하나를 텐서플로우로 훈련시키고 우리의 앱에서 사용할 것입니다.
만약 당신이 텐서플로우에 익숙하지 않다면, 여기서 배울 수 있지만, 이 게시글은 당신이 모델을 훈련시키기 위한 모든 설명을 가지고 있습니다. 저의 신경 네트워크는 전문가를 위한 Deep MNIST에서 쓰인 텐서플로우 튜토리얼에 기반을 두고 있습니다.
제가 모델을 훈련시키고 추출할 때 사용한 스크립트들은 gesturelearner라는 폴더에 있습니다. 저는 보통의 사용 방법을 따라 갈 것지만, 유용한 추가 커맨드라인 옵션들도 있습니다. virtualenv 설정하는 것부터 시작하겠습니다:
cd /path/to/gesturelearner
# coremltools가 파이썬 3을 지원하기 전까지, 파이썬 2.7을 사용합니다.
virtualenv -p $(which python2.7) venv
pip install -r requirements.txt
데이터 셋 준비하기
먼저, 저는 데이터 셋을 15%의 “테스트 셋”과 85%의 “훈련 셋”으로 나누기 위해 filter.py를 사용합니다.
# virtualenv 활성화
source /path/to/gesturelearner/venv/bin/activate
# 데이터 셋 나누기
python /path/to/gesturelearner/filter.py --test-fraction=0.15 data.trainingset
훈련 셋은 당연하게도 신경망을 훈련하기 위해 사용됩니다. 훈련 셋의 목적은 신경망이 새로운 데이터에 얼마나 잘 적용되는지 보여주는 것입니다 (예. 네트워크가 그냥 훈련 셋의 제스쳐의 레이블을 기억하는 것이지 아니면 근본적인 패턴을 발견하는 것인지)?
저는 15%의 데이터를 훈련 셋을 위해 따로 빼두었습니다. 만약 당신이 총 몇 백 개의 제스쳐 예제밖에 없다면, 15%는 아마 작은 수가 될 것입니다. 그 말인 즉슨, 훈련 셋의 정확도는 당신에게 알고리즘이 어떻게 작동하는지에 대한 러프한 아이디어만 줄 것입니다.
이 부분은 선택입니다. 궁긍적으로 네트워크 작동이 얼마나 잘 되는지를 알아보는 가장 최고의 방법은 당신의 앱에 넣어보고 시험해보는 것입니다.
훈련시키기
저의 커스텀 .trainingset 포맷을 텐서플로우가 좋아하는 TFRecords 포맷으로 변환한 후에, 저는 train.py를 모델을 훈련하는데에 사용합니다. 여기가 마법이 일어나는 곳입니다. 신경망이 미래에 마주칠 새로운 제스쳐를 견고하게 분류하기 위해 우리가 제공한 예제를 배우는 곳입니다.
train.py는 그것의 처리 과정을 출력하고, 주기적으로 텐서플로우 체크포인트 파일을 저장하고, 그것의 정확도를 테스트 셋에서 테스팅합니다 (명시되어 있다면요).
# 만들어진 파일을 텐서플로우 TFRecords 포맷으로 변환합니다
python /path/to/gesturelearner/convert_to_tfrecords.py data_filtered.trainingset
python /path/to/gesturelearner/convert_to_tfrecords.py data_filtered_test.trainingset
# 신경망을 훈련시킵니다
python /path/to/gesturelearner/train.py --test-file=data_filtered_test.tfrecords data_filtered.tfrecords
훈련은 빨라야 하고 1분 안에 98%의 정확도에 도달해야 하고 10분 후에 안정화돼야 합니다.
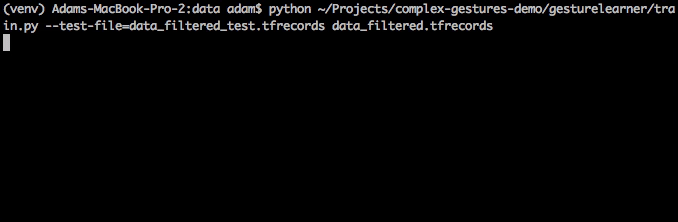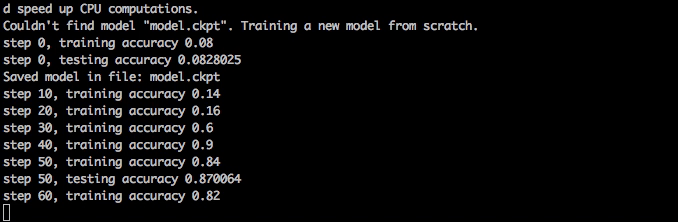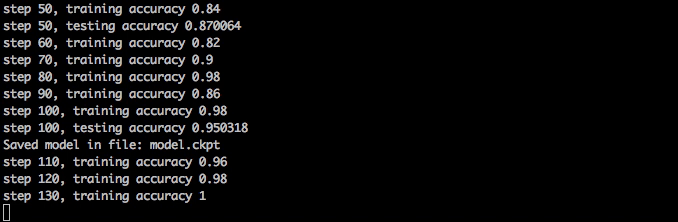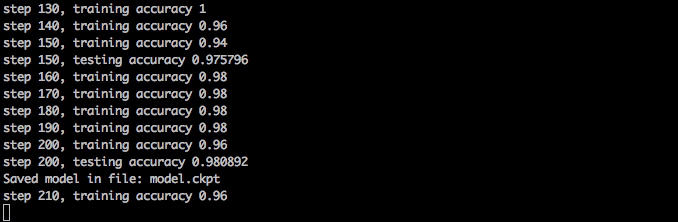 신경망 훈련시키기
신경망 훈련시키기
만약 훈련 도중에 train.py를 종료한다면, 당신은 나중에 다시 시작할 수 있고 그것은 체크포인트 파일을 불러오고 어디서 꺼졌는지 확인할 것입니다. 그리고 그것은 어디서 모델을 불러올 것인지와 어디서 저장할 것인지에 대한 옵션을 가지고 있습니다.
기울어진 데이터로 훈련하기
만약 당신이 몇몇 제스쳐의 예제를 다른 제스쳐에 비해 상당히 많이 가지고 있다면, 네트워크는 다른 제스쳐들을 희생해가며 잘 표현된 제스쳐를 인식하는 것을 배우는 경향이 있습니다. 이것에 대처하기 위한 몇가지 다른 방법이 있습니다:
- 신경망은 에러를 만들면서 비용 함수 최소화하는 식으로 훈련됩니다. 특정 클래스를 무시하는 것을 피하기 위해, 분류를 잘못하는 비용을 증가시킬 수 있습니다.
- 적게 표현된 제스쳐들의 복사본을 포함하면 모든 제스쳐에 대한 같은 수를 가질 수 있습니다.
- 많이 표현된 제스쳐들의 몇가지 예제를 삭제합니다.
제 코드는 위와 같은 특별 취급을 하진 않지만, 이것들은 상대적으로 구현하기 쉽습니다.
Core ML로 내보내기
제가 시사했듯이, Core ML은, 예를 들어, Caffe와 scikit-learn처럼 텐서플로우 모델을 Core ML MLModel로 변환하는 “변환기”를 가지고 있지 않습니다. 이것은 우리에게 신경망을 MLModel로 변환하는 두 가지 옵션을 줍니다:
- 신경망을 구축하기 위한 API를 가지고 있는 coremltools.models 패키지 사용하기
- MLModel의 설명서가 구글의 프로토콜 버퍼에 기반을 두고 있기 때문에, 당신은 coremltools를 건너뛰고 아무 언어로 가상의 protobuf를 직접적으로 사용하기
지금까지 기존의 변환기의 내부 코드외에 웹에서의 두 가지 방법의 예제밖에 없었던 걸로 보입니다. 여기 coremltools를 사용한 제 예제의 압축버전이 있습니다:
이것을 사용하려면:
# 텐서플로우의 체크포인트 model.ckpt에서 Core ML .mlmodel 파일을 저장합니다
python /path/to/gesturelearner/save_mlmodel.py model.ckpt
전체 코드는 여기서 확인할 수 있습니다. 몇가지 이유로 당신이 coremltools를 건너뛰고 MLModel protobuf와 직접적으로 작업하려면, 당신은 또한 이 코드에서 어떻게 하는지 볼 수 있습니다.
이 변환 코드를 직접 작성하는 것의 하나의 부작용은 우리의 전체 네트워크를 두 곳(텐서플로우 코드, 그리고 변환 코드)에서 설명해야 한다는 것입니다. 텐서플로우 그래프를 바꾸는 어느 시간이든, 우리는 변환 코드를 동기화하고 우리의 모델이 적절한 추출결과를 내는지 확인해야 합니다.
미래엔 애플이 텐서플로우 모델을 내보내기 위한 더 나은 메소드를 개발하기를 바랍니다.
안드로이드에선 여러분은 공식 지원하는 텐서플로우 API를 사용할 수 있습니다. 구글은 또한 텐서플로우의 모바일 최적화 버전인 텐서플로우 라이트(TensorFlow Lite)를 출시할 것입니다.
3. 앱 안에서 제스쳐 인식하기
마지막으로, 우리의 모델을 유저와 만날 앱에게 장착시켜 봅시다. 프로젝트의 이 부분은 GestureRecognizer이고, 앱은 이 게시글의 시작부분의 이미지에서 확인할 수 있습니다.
mlmodel 파일을 가지고 있으면, Xcode의 타겟에 추가할 수 있습니다. Xcode 9가 필수입니다. 지금은 퍼블릭 베타이지만, 새로운 아이폰과 iOS 11이 나올 다음주에 같이 배포될 것입니다.
Xcode 9은 당신이 타겟에 추가한 어떤 mlmodel 파일도 컴파일 가능할 것이고 그들에 맞는 스위프트 클래스를 만들어 줄 것입니다. 저는 저의 모델을 GestureModel로 지었고 그래서 Xcode는 GestureModel, GestureModelInput, 그리고 GestureModelOutput 클래스를 만들었습니다.
우리는 유저의 제스처(Drawing)를 GestureModel이 받아들인 포맷으로 변환해야 합니다. 그것은 우리가 스텝 1에서 했던 제스쳐를 그레이스케일 이미지로 바꾸는 작업을 의미합니다. 그러고 나서 Core ML은 그레이스케일 값의 배열을 다차원 배열 타입인 MLMultiArray으로 변경하는 작업을 요구합니다.
MLMultiArray는 Core ML에게 어떤 타입을 포함하고 있는지와 어떤 모양(예. 차원)을 가지고 있는지를 말해주는 가공되지 않은 배열을 감싸는 래퍼와 같습니다. MLMultiArray를 사용하면, 우리는 우리의 신경망을 평가할 수 있습니다.
저는 각 인스턴스를 할당하는 데 상당한 시간이 걸리는 것처럼 보이기 때문에 GestureModel의 공유 인스턴스(싱글톤)를 사용합니다. 사실, 심지어 인스턴스가 생성된 이후에도 모델은 처음엔 느립니다. 저는 어플리케이션이 시작할 때 네트워크를 빈 이미지로 평가하게 해서 유저가 처음 제스쳐를 그릴 때 딜레이를 느낄 수 없게 만듭니다.
네트워크의 결과 통역하기
위의 함수는 각 가능한 제스쳐 클래스(레이블)에 대해 “확률”의 배열을 출력합니다. 더 높은 값은 일반적으로 더 높은 신뢰를 보여주지만, 클래스에 속하지 않는 많은 제스쳐들은 반-직관적으로 높은 점수를 받습니다.
1부에서 저는 인식 가능한 제스쳐들중에 인식 불가능한 것을 확실하게 구별하는 방법에 대해 말했었습니다. 한 가지 해결책은 “인식 불가능한 제스쳐” 카테고리를 어디에도 속하지 못 한 다양한 종류의 다른 제스쳐들로 구성하는 방법입니다. 이 프로젝트에선 저는 그냥 네트워크가 제스쳐를 “확률”로 분류하고 특정 한계점(0.8)을 넘으면 인식 가능하다고 생각했습니다.
제스쳐 간의 충돌 피하기
제가 사용하는 제스쳐 클래스들은 서로 포함하고 있기 때문에(웃는 얼굴은 U 모양 입을, x 모양은 오른쪽 위 대각선을), 유저가 더 복잡한 것을 그리기 전에 성급하게 더 간단한 제스쳐를 인식해버리는 일이 가능합니다.
이 충돌을 줄이기 위해, 저는 두 가지 간단한 규칙을 적용했습니다:
- 제스쳐가 어떤 더 복잡한 제스쳐의 부분일 수 있다면, 유저가 더 큰 제스쳐를 그릴지 보기 위해 잠시 제스쳐의 인식을 미룹니다.
- 유저가 그린 스트로크의 개수를 보고 아직 그려지지 않은 제스쳐는 인식하지 않습니다. (예. 웃는 얼굴은 두 눈과 입으로 인해 최소 3개의 스트로크가 필요합니다.)
하지만 보통, 높은 탄탄함과 반응성을 위해 당신은 서로 포함하지 않을 제스쳐를 골라야 합니다.
끝입니다! 이 설정으로 인해, 당신은 완벽하게 새로운 제스쳐를 당신의 iOS 앱에 20분만에 추가할 수 있게 되었습니다 (100개의 입력 이미지, 99.5%이상의 정확도로 훈련, 모델로 내보내기).
이 조각들이 어떻게 서로 맞춰지는지 또는 그것들을 당신의 프로젝트에 사용하고 싶다면, 전체 소스 코드를 확인하세요.
저에게 당신의 iOS나 안드로이드 앱을 맡기고 싶으십니까? 연락주세요